Background
笔记内容不涉及编译器实现
Textbook: 虎书ML版(Modern Compiler Implementation in ML)
Chapters: 1-12
编译器组成结构

(图片来自虎书第四页)
编译器可分为Front-end, Middle-end, Back-end.
- Front-end:
- 词法分析(Lexical Analysis) 将输入的character stream(代码)parse 成 token stream。使用工具为:lex/flex(用regular expression匹配)
- 句法分析(Syntax Analysis) 根据语言的语法结构将tokens parse 生成abstract syntax tree.
- Middle-end: 语义分析(Semantic Analysis) 检查程序是否可编译(type check AST 确保每个exp都有正确的type)然后将AST translate成IR tree(intermediate representation tree)
- Back-end: 规范化(canonicalization & linearization)指令选择,控制流分析,数据流分析,寄存器分配,指令流出,整合,优化。
Front-end
chapter 1-4
Part 1 词法分析
使用正则表达式将程序(此时的程序是concrete syntax)匹配成token。tokens分成numbers,identifiers,punctuation,key words等等。
正则表达式的规则很容易理解,但是正则表达式并不能直接用来解析字符串,所以我们还要引入一种适合转化为计算机程序的模型—–有穷自动机(finite automation,FA)
根据正则表达式画出非确定性有穷自动机(NFA),因为NFA简单,易于思考。但是计算机硬件对于NFA的猜测能力实现起来很困难,所以我们要把NFA转化为确定性有穷自动机(DFA)。
有很多工具可以实现lexical analysis,我们在这里使用flex。
Part 2 句法分析
目的是构建AST(Abstract Syntax Tree)。因为一种完整的编程语言,必须在 stream of tokens 的基础上定义出各种声明、语句和表达式的语法规则。
观察我们所熟悉的编程语言,其语法大都有某种递归的性质。例如四则运算与括号的表达式,其每个运算符的两边,都可以是任意的表达式。比如1+a是表达式,(1+a)/(2 – c)也是表达式,((a+b) + c) / (d – e)也是表达式。再比如if语句,其if的块和else的块中还可以再嵌套if语句。我们在词法分析中引入的正则表达式和正则语言无法描述这种结构,如果用DFA来解释,DFA只有有限个状态,它没有办法追溯这种无限递归。所以,编程语言的表达式,并不是正则语言。我们要引入一种表现能力更强的语言——上下文无关语言。
上下文无关文法
产生式
我们假设表达式只有三种——单个表示变量名标识符、括号括起来的表达式和两个表达式相加。比如a是一个变量表达式,a+b是两个变量表达式相加的表达式,(a+b)是一个括号表达式。我们用符号E来表示一个表达式,那么这三种表达式分别可以定义为:
E → id E → E + E E → E * E E → ( E )这种形式的定义就叫做产生式(production)。出现在→左侧符号E称作非终结符(nonterminal symbol),代表可以继续产生新符号的“文法变量”。 符号→右侧表示非终结符可以“产生”的东西。而上述产生式中的id、+、(等符号,是具有固定意义的token,它们不再会产生新的东西,称作终结符(terminal symbol)。
注意,非终结符可以出现在产生式的右侧,这就是具有递归性质文法的来源。产生式经过一系列的推导(derivation),就能够生成各种完全由终结符组成的句子。比如,我们演示一下表达式(a + b) + c的推导过程:
E => E + E => (E) + E => (E + E) + E => (a + E) + E => (a + b) + E => (a + b) + c以上推导过程中,我们每次都将句型中最左边一个非终结符展开,所以这种推导称为最左推导。当然也有最右推导,不同之处就算是每次将句型中最右边的非终结符展开:
E => E + E => E + c => (E) + c => (E + E) + c => (E + b) + c => (a + b) + cLL parse 和 LR parse
- LL 意思是 from left to right,left most derivation;LR 意思是 from left to right,Right most derivation。
- LL输出解析树的先序遍历,LR后序遍历。
- LL产生最左导出,LR产生逆转最右导出。
- LL 是Top-down build 解析树;LR 是 Bottom-up build 解析树
LL 是 predictive parser,是递归下降;LR 是 shift-reduce parser。一次shift-reduce是把右边替换成左边的过程,也就是推导的逆过程,是某次R-derivation 的逆过程。所以是bottom up 构建解析树。举例如下:
在LL解析过程中,解析器不断地在两个操作中进行选择: 预测:选择应该应用哪种production来输入字符串。 匹配:输入最左边未启用的符号来进行匹配。 例如, S → E E → T + E E → T T → int 然后给出字符串int + int + int,LL(2)解析器,如下所示: Production Input Action --------------------------------------------------------- S int + int + int Predict S -> E E int + int + int Predict E -> T + E T + E int + int + int Predict T -> int int + E int + int + int Match int + E + int + int Match + E int + int Predict E -> T + E T + E int + int Predict T -> int int + E int + int Match int + E + int Match + E int Predict E -> T T int Predict T -> int int int Match int Accept 这个过程一般是用预测分析表来做,根据表达式找到first、follow、nullable sets。超前查看n就是把可能的follow也考虑进去。 在LR解析器中,有两个操作: Shift::向缓冲区中添加下一个输入token Reduce::选择一个grammar rule,从workspace中pop出token然后push →左侧的非终结符进去。 Go to::start next thing 如下所示: Workspace Input Action --------------------------------------------------------- int + int + int Shift int + int + int Reduce T -> int T + int + int Shift T + int + int Shift T + int + int Reduce T -> int T + T + int Shift T + T + int Shift T + T + int Reduce T -> int T + T + T Reduce E -> T T + T + E Reduce E -> T + E T + E Reduce E -> T + E E Reduce S -> E S Accept
消除二义性,消除conflicts
如果一个grammar可以推导出一条具有不同语法树的sentence,那么这个grammar就是ambiguous grammar。还是用 产生式 小节中的grammar 举例,a+b*c 就有两个不同的解析树
最左推导1:E => E + E => E * E + E => a * E + E => a * b + E => a * b + c 最左推导2:E => E * E => a * E => a * E + E => a * b + E => a * b + c我们一般通过文法转换也就是修改grammar增加辅助non terminal token 来消除ambiguous。
冲突有Shift-Reduce conflict和Reduce-Reduce Conflict。我们常用两种方法来解决冲突。
- 改变优先级
增加辅助 non terminal
关于优先级指导(在yacc中的优先级指导)有如下几点特点:
- 规则(rule)的优先级由该规则的最后出现的token(终结符)决定。
- 当规则和token的优先级相等时,用%left 指明的优先级偏向于reduce,%right 指明的偏向于shift,而%nonassoc 则导致error
- %prec命令可以给rule指定一种明确的优先级。例如:UMINUS。%prec UMINUS 给了规则 exp:MINUS exp最高优先级。常用来解决负数问题。
抽象语法
根据上述知识我们可以构建source language的上下文无关文法(就是写他们的production)。在虎书中就是完成tiger.grm文件。使用的工具叫做YACC。编译器的前端工作在识别一个句子是属于source language(符合source language的语法规则,也就是符合它的文法)之后,它还要对那个句子做一些事情,称为语义动作(semantic action)。在递归下降的语法分析器中,语义行为是parsing function返回的值或这些函数的副作用(side effects)或同时是这二者。
AST(抽象语法树)是一种数据结构,为了更好的模块化编译器,将语法问题与语义问题分开处理,我们需要生成AST。抽象语法起一个接口作用。
Middle-end
编译器的middle-end 是对front-end构建的AST遍历进行语义分析,同时将生成intermediate representation tree。在这个阶段,最重要的是检查语句是不是compilable。语义分析是编译器前端最复杂的部分。
类型检查
所谓编程语言语义,就是这段代码实际的含义。编程语言的代码必须有绝对明确的含义,这样人们才能让程序做自己想做的事情。比如最简单的一行代码:a = 1; 它的语义是“将32位整型常量存储到变量a中”。首先我们对“1”有明确的定义,它是32位有符号整型字面量,这里“32位有符号整型”就是表达式“1”的类型。其次,这句话成为合法的编程语言,32位整型常量必须能够隐式转换为a的类型。假设a就是int型变量,那么这条语句就直接将1存储到a所在内存里。如果a是浮点数类型的,那么这句话就隐含着将整型常量1转换为浮点类型的步骤。在语义分析中,类型检查是贯穿始终的一个步骤。
Symbol table是语义分析阶段主要用到的数据结构。符号表(环境)是由绑定构成的集合。
Contains entries mapping identifiers to their bindings (e.g. type)
As new type, variable, function declarations encountered, symbol table augmented with entries mapping identifiers to bindings.
When identifier subsequently used, symbol table consulted to find info about identifier.
When identifier goes out of scope, entries are removed.
有两种symbol table的实现方式:
functional style(无副作用)
- When beginning-of-scope entered, new environment created by adding to old one, but old table remains intact.
- When end-of-scope reached, retrieve old table.
imperative style(副作用)
- Global symbol table
- When beginning-of-scope entered, entries added to table using side-effects. (old table destroyed)
- When end-of-scope reached, auxiliary info used to remove previous additions.(old table reconstructed)
在tiger 的compiler中,我们需要两个环境,一个Type environment(maps type symbol to type that it stands for),一个Value environment(maps variable symbol to its type)
AR 活动记录 Activation Records
在现代程序语言中的局部变量都是在函数的入口创建,在函数return的时候摧毁。
对函数的每次调用都会 has its own instantiation of local variables:
Recursive calls to a function require several instantiations to exist simultaneously.
Functions return only after all functions it calls have returned µ last-in-first-out (LIFO) behavior.
A LIFO structure called a stack is used to hold each instantiation.
The portion of the stack used for an invocation of a function is called the function’s stack frame or activation record.

就像冰锥一样,从上往下生长。saved registers 后面 stack pointer前面是outgoing args。就像frame pointer前面的incoming args 一样。
举例说明:
- function g(…) calls f(a1,…,an)
- 在进入f(…)的时候,SP points to first arg that g() passes to f(). Allocate a frame(新的frame)。SP - Frame size
- old SP 就是新的 FP
- Frame size要很晚才知道。因为要等到memory-resident temporaries and saved registers 确定了
- 如果callee需要在memory中写入任何incoming args,put them in ”local vars“ in frame;caller f() 将a1…ak 放入register,将ak+1 … an 放入frame tail (outgoing args)
- caller的outgoing args就是callee 的incoming args
关于variable 逃逸:
A variable escapes if:
- it is passed by reference,
- its address is taken, or
- it is accessed from a nested function.
关于 Stack Frame 和 Registers:
Registers hold:
- Some Parameters
- Return Value
- Local Variables
- Intermediate results of expressions (temporaries)
Stack Frame holds:
- Variables passed by reference or have their address taken (&)
- Variables that are accessed by procedures nested within current one.
- Variables that are too large to fit into register file.
- Array variables (address arithmetic needed to access array elements).
- Variables whose registers are needed for a specific purpose (parameter passing)
- Spilled registers. Too many local variables to fit into register file, so some must be stored in stack frame.
关于 Static Link:
- SL是FP指着的第一个,也就是incoming args的第一个。
- SL是a pointer to the frame of the function statically enclosing calle
- 自己call 自己,传的是自己的SL不是FP
- 同级别(level)的function,SL一样。 g() calls d(), d() nested in f(), d()的SL是f() 的FP。
寄存器
The assignment of variables to registers is done by the Register Allocator.
Caller-save register are the responsibility of the calling function.
Caller-save register values are saved to the stack by the calling function if they will be used after the call.
The callee function can use caller-save registers without saving their original values.
Callee-save registers are the responsibility of the called function.
Callee-save register values must be saved to the stack by called function before they can be used.
The caller (calling function) can assume that these registers will contain the same value before and after the call.
Placement of values into callee-save vs. caller-save registers is determined by the register allocator.
翻译 Translate to IR Tree
翻译成IR Tree是为了更好的模块化。因为source code和target code有很多种。
Intermediate Representation (IR):
An abstract machine language
Expresses operations of target machine
Not specific to any particular machine
Independent of source language
函数的Prologue 和Epilogue
Prologue precedes body in assembly version of function:
Assembly directives that announce beginning of function.
Label definition for function name.
Instruction to adjust stack pointer (SP) - allocate new frame.
Instructions to save escaping arguments into stack frame, instructions to move nonescaping arguments into fresh temporary registers.
Instructions to store into stack frame any callee-save registers used within function.
Epilogue follows body in assembly version of function:
Instruction to move function result (return value) into return value register.
Instructions to restore any callee-save registers used within function.
Instruction to adjust stack pointer (SP) - deallocate frame.
Return instructions (jump to return address).
Assembly directives that announce end of function.
- Steps 1, 3, 8, 10 depend on exact size of stack frame.
- These are generated late (after register allocation).
- Step 6: MOVE(TEMP(RV), unEx(body))
Back-end
后端进行优化,指令选择,control flow analysis,data flow analysis,register allocation 等等。
Linearization and Canonicalization
翻译完成之后的IRTree 有问题:ESEQ和CALL node含有assignment语句和input/output,不能按照任意顺序执行。
真正的机器语言:
- CJUMP 在 false时下降到下一条指令(fall through)
- 对于ESEQ,不同的计算顺序有不同的结果
- 对于CALL,不同的计算顺序有不同的结果
- CALL nodes within argument list of CALL nodes cause problems of args passed in specialized registers。
所以我们要对IR树进行规范化处理,得到规范树:
1. 无ESEQ/SEQ
2. 每一个CALL的父亲不是EXP(...)就是MOVE(TEMP t, ...)
Canonicalization:
- 提升SEQ,ESEQ,bottom up
- 消除SEQ,ESEQ,使得只有一个SEQ在top,把它改成list。
- 提升CALL,让它surrounded by EXP or MOVE
没有副作用就可以提升,这里有一个commute的概念:常数,空语句可以与任何exp交换,其他的都不行。
Canonicalization之后所有的SEQ都在树顶,进行Linearization。
CJUMP也要经过处理,使得下一条指令是False label。
Basic Block:
- first stm is LABEL
- The last stm is a JUMP or CJUMP
- No other LABEL,JUMP or CJUMP
Trace:A sequence of statements that could be consecutively executed during the execution of the program.
Instruction Selection
Instruction Selection 是 Process of finding set of machine instructions that implement operations specified in IR tree.
Each machine instruction can be specified as an IR tree fragment(tree pattern).
就相当于用瓦片(tile)来不断的覆盖IR tree。一个瓦片就是一个tree pattern that corresponding to one instruction。
这个阶段的目标是:cover IR tree without overlapping tree pattern.
所以就会有两个概念:Optimal 和 Optimum Tilings. Optimum is also Optimal 但反之不是。
- Optimal: no two adjacent tiles can be combined into a lower cost tile
- Optimum: tiles sum to the lowest cost
有两种算法来覆盖IR tree,一种用了动态规划,另一种就是普通的maximum munch(从root开始,找最大的tile,重复该过程;从相反的方向生成代码)。
Liveness Analysis
在IR tree中我们假设的是有无限多的register。但是实际计算机上,寄存器的个数是有限的。如果两个变量a,b不会同时处于“使用中”,则可以把他们放在同一个寄存器中。如果一个变量在将来还要使用,则称这个变量是“活跃的”。
进行活跃分析需要画出控制流图(control flow graph)。程序中每个语句都是图中的一个节点,如果语句x之后跟着语句y,则会有一条从x到y的边。
Control Flow Analysis
- Control Flow Analysis determines the how instructions are fetched during execution.
- Control Flow Analysis precedes dataflow analysis.
- Dataflow analysis determines how data flows among instructions.
- Dataflow analysis precedes optimization, register allocation, and scheduling.
根据CFG画出冲突图,进行活跃分析。
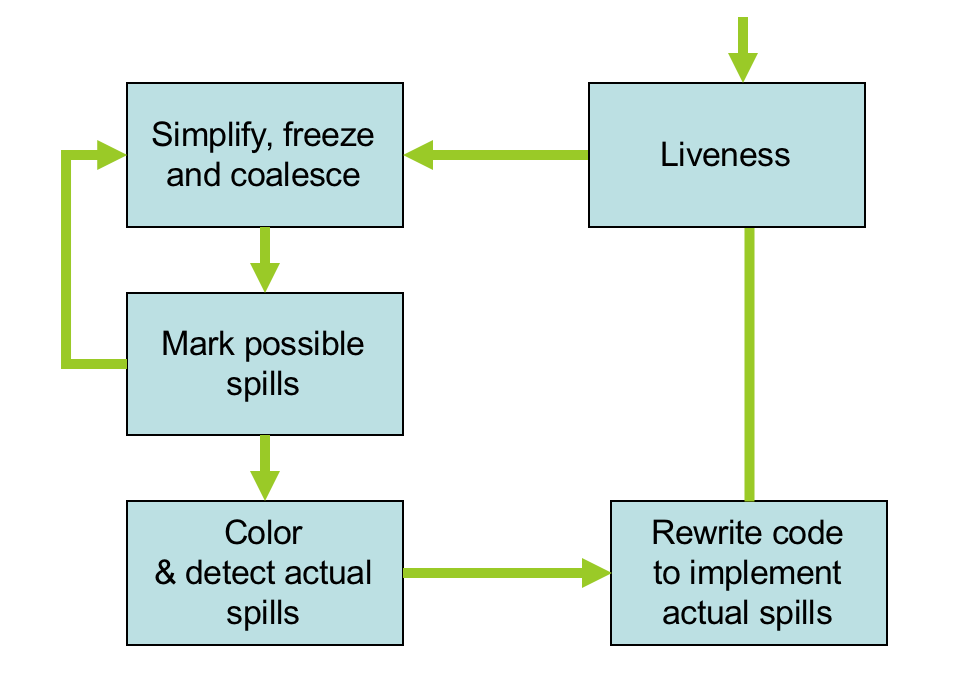
寄存器分配
寄存器分配实际上是个着色问题。
冲突图的每一个节点代表一个临时变量,每条边(t1,t2)指出一对不能分配到同一寄存器的临时变量。产生冲突的最常见原因就是两个变量同时活跃。
然后我们要给冲突图着色,每一种颜色代表着一个寄存器。我们希望用尽可能少的颜色(尽可能少的寄存器)。如果target machine有K个寄存器,则可以用K种颜色给图着色。最后得到的着色就是关于这个冲突图的一种合法的寄存器分配。如果不存在K色着色,我们就必须将一部分变量和临时变量存在memory中,这称之为溢出(spilling)。
我们采用 Kempe 的算法for finding a K-coloring of a graph。
Assume K=3
Step 1 (simplify): find a node with at most K-1 edges and cut it out of the graph. (Remember this node on a stack for later stages.)
Once a coloring is found for the simpler graph, we can always color the node we saved on the stack
Step 2 (color): when the simplified subgraph has been colored, add back the node on the top of the stack and assign it a color not taken by one of the adjacent nodes
有时候the graph cannot be colored, it will eventually be simplified to graph in which every node has at least K neighbors
但是Sometimes, the graph is still K-colorable! 如果我们不能成功着色。
Step 3 (spilling): once all nodes have K or more neighbors, pick a node for spilling
Some variables are pre-assigned to registers。Treat these registers as special temporaries; before beginning, add them to the graph with their colors
* Can’t simplify a graph by removing a precolored node
* Precolored nodes are the starting point of the coloring process
* Once simplified down to colored nodes start adding back the other nodes as before
Simplify & Coalesce:
Step 1 (simplify): simplify as much as possible without removing nodes that are the source or destination of a move (move-related nodes)
Step 2 (coalesce): coalesce move-related nodes provided low-degree node results
Step 3 (freeze): if neither steps 1 or 2 apply, freeze a move instruction: registers involved are marked not move-related and try step 1 again
完整的过程如图所示: